While search-bars are a great convenience we don’t appreciate enough, a new age of searching based on a more sophisticated analysis platform is coming to make the search-bar better than ever. Dextro, making videos searchable and curatable, is using new technology developed by a team of robotic scientists to recognize the fine details within a video. What you see in a video is now being picked up by their system…even the random apple that makes a cameo performance in a video.
David Luan, Founder and CEO of Dextro tells us about his newly launched company and how he is taking on this large market.
Tell us about the product or service.

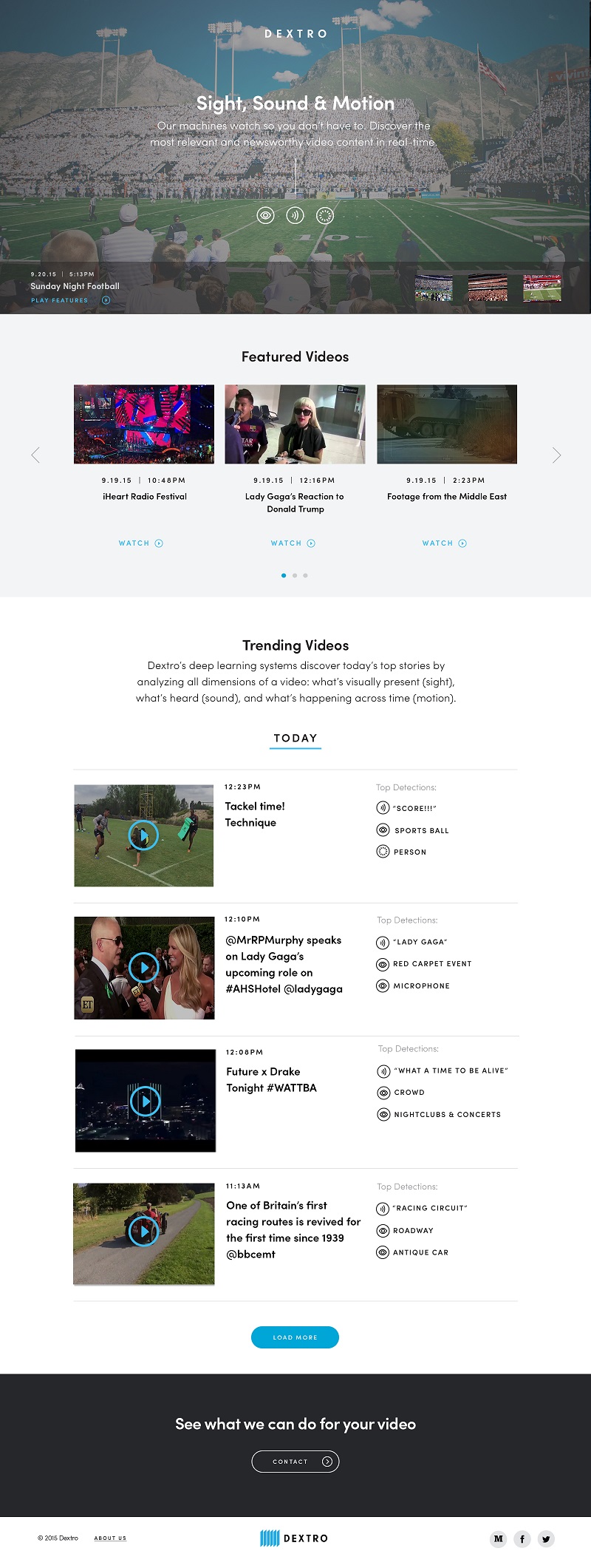
Dextro is a SoHo-based computer vision and machine learning company that makes videos searchable, discoverable, and understandable by machines. We just launched our newest video analysis platform, “Sight Sound and Motion” (SSM). SSM enables computers to analyze and categorize video content based on all the different visual, auditory, and motion cues happening onscreen. Unlike traditional text-based searching, which relies on simple keyword matching on metadata, SSM develops a comprehensive understanding of what’s happening in the video itself using deep learning.
How is it different?
Dextro works exclusively with video, which is much more challenging than image classification. We were the first company to figure out how to analyze live video in real time in May 2015.
With SSM, for the first time, every dimension of a video that a human sees–the visuals, audio track spoken, and motion that happens across time–is being processed and analyzed. SSM eliminate the pain point of endlessly browsing poorly or inadequately tagged clips. Instead, we enable users, editorial teams, content curators, and companies that manage large volumes of video files to locate, filter, and share videos based on precise search parameters over the contents of videos themselves.
What market are you attacking and how big is it?
Dextro is in a brand-new space: automatically understanding video. Today, there already are billions of hours of video on the web. Every minute, 300 hours of video are uploaded to YouTube alone, not to mention all other platforms; by 2019, 80% of all web traffic will be video content.[1] With this much video, an automated solution like Dextro is required to be able to act on the data and monetize it.
[1] http://www.reelseo.com/youtube-300-hours/
http://www.reelseo.com/2019-internet-video-traffic/
Today, with SSM, Dextro serves content providers as they make their own content discoverable and searchable. We also help companies rapidly find the best, most relevant videos. Later down the line, we envision the technology to be used in areas like citizen journalism, security and public safety, manufacturing and robotics.
What is the business model?
Dextro bills on a usage model.
What is the value of data in videos?
Users, editorial teams, and curators waste a lot of time scrolling through overwhelmingly long lists of video to find good content. And hashtags are little help; there were 672 million hashtags about the World Cup in 2014 alone.
The crux of the problem is that we are relying on text descriptors – hashtags, captions, geotags, titles – to categorize and find video. The only permanent solution is to analyze the visual elements of the video itself, instead of relying on the text associated with it. Computer vision – where computers analyze the content of videos – can do so in a matter of seconds.
We all can appreciate the power of video to transform the way we experience and understand the world. We live life in motion, and that information can only be fully captured by video. By teaching computers how to see, listen, and comprehend what is happening within a video file or a live stream, we can finally make the data embedded in videos usable for search, discovery, and monetization.
What inspired the business?
Half of the Dextro team has a robotics background: MIT, iRobot, GRASP Lab, SRI, etc. Dextro was started when we realized that one of the largest problems facing widespread robotics adoption was perception, specifically the ability of robots to parse complex human scenes from its cameras. Our early prototypes for roboticists in the maker/hacker movements in 2013 turned into a #1 story on HackerNews and a deluge of inbound customer inquiries for markets unrelated to robotics. We realized then that our system could generalize and help solve video understanding problems in many markets.
What are the milestones that you plan to achieve within six months?
We’re focused on continuing to push out new innovations on the algorithms side for understanding video. We’re also rapidly growing our team, both on the engineering as well as on the business sides.
If you could be put in touch with one investor in the New York community who would it be and why?
Good question—we’re privileged to work with a bunch of great NYC investors in our first financing.
Why did you launch in New York?
NYC is an amazing place for computer vision. We chose NYC because we’re able to put together a stellar team of machine learning PhDs and MSs and data scientists used to working with visual content. We’re surrounded by great talent in the area. We’re also lucky to be able to share ideas with the high density of influential people in academia nearby: Serge Belongie at Cornell Tech, Jianxiong Xiao at Princeton, Rogerio Feris at IBM Research, plus the greater ecosystem in Boston.
Where is your favorite place to visit in the area in the fall?
Biking through Prospect Park and points south in Brooklyn is amazing. Perfect temperature, the smell of wood, and the changing of foliage reminds me in a pleasant way of the passage of time.